머신러닝 00. 통계적 분석은 왜, 어떻게 사용할까? (feat.머신러닝)
Written on October 21st , 2019 by MJ 목차
1. 통계는 어떻게 현실 문제를 해결하고 머신러닝은 또 뭘까?
2. 머신러닝 기법의 종류?
3. 구체적으로…
(1) 데이터 축소화 분석(data reduction)
(2) 축소화/유형화 분석의 종류
- 관찰치를 묶어서 데이터를 축소함: 군집분석 / 다차원척도분석 / 연관분석
- 변수컬럼을 묶어서 데이터를 축소함: 주성분 분석 / 요인분석
4. 연관분석(A Priori Algorithm)
5. 군집분석(clustering)
(1) 크게 2가지 방식의 군집분석 기법이 있음: 계층적 / 분할적
6. 주성분분석(Principal Component Analysis)
7. 요인분석(Factor Analysis)
(1) 주성분분석과 요인분석의 공통점
(2) 주성분분석과 요인분석의 차이점
8. 비교차이(A/B테스트)와 예측분석(prediction)
(1) A/B/n Test
(2) Prediction Test
(3) 회귀분석(regression)
9. 분류분석(classification)
10. A/B테스트와 회귀분석을 통한 동일한 문제에 대한 차별적 접근
추가. 몇가지 용어 정리
1. 통계는 어떻게 현실 문제를 해결하고 머신러닝은 또 뭘까?
우리 주변에는 다양한 데이터가 있다. 앞사람의 머리카락 색, TV 속 연예인 목소리의 리듬과 톤, 도로 위 교통 상황과 자동차의 위치 등이다. 이들은 객관적 사실로서 어디에나 존재하지만 누구도 거기에 특별한 의미를 부여하지 않는다. 그러나 누군가가 이것을 이용해야할 때(관심이 있을 때), 예를 들면 도로 주행의 최단거리를 찾거나 어떤 머리카락 색이 어뗜 효과를 주는지 찾는 등의 질문 거리에 대한 답을 찾고 싶을 때, 평범한 사실을 의미를 가진 정보의 집단으로 처리될 수 있다. 그리고 어떤 정보 집단이든 내부 숫자에 대한 통계를 낼 수 있다. 이때, 많은 데이터는 연속적인 숫자이지만, 또다른 많은 데이터는 범주로 주어지거나 (yes or no) 물질적 항목 그 자체이다. 이것은 어떻게 숫자일까? 정의를 조금 다르게 내려보면 된다. 진한 갈색은 1, 그냥 갈색은 0.7, 연한 갈색은 0.4 처럼, 마치 자로 재듯 척도를 가지고 측정을 할 수 있다. 그리하여 이 숫자들로는 통계를 낼 수 있다. 즉, 어떤 집단의 자료를 정리, 요약해서 그 집단을 설명할 수 있는 수치를 찾을 수 있고, 때때로 그 수치로부터 보다 광범위한 집단을 타당하게 설명(추정) 할 수도 있고, 시간이나 공간 등의 조건이 다를 때의 집단이 어떻게 변할지 타당하게 추정해볼 수도 있다. 즉 평균과 분산을 가지고, 확률분포를 가정할 수 있고, 여러가지 법칙과 정리도 따르며, 추정이나 검정이 가능하다.
어떤 현상을 수학적으로 표현하면 패턴과 법칙을 발견하는데 편리하다. 통계적인 방법을 사용하면 각종 현상을 설명하고 추측하는데 유리하다. 통계적 분석이란 건 여러가지 문제를 해결하는 이 꽤 괜찮은 방법들을 한데 모아 ‘분석’이라는 단어를 붙인 듯하다.
회귀분석은 전통적으로 사용하던 통계적 분석 방법이다. 더 간단하고 모두가 들어봤을 예시는 평균과 표준편차이다. 수능을 치면 주어지던 표준점수가 이 기본 통계 지식을 적용해 학생들의 시험점수를 통계적으로 분석한 결과이고, 그 결과와 그외 평가지표를 취합해서 대학은 각 학생의 합격과 불합격을 논리적으로 타당하게 선고한다. 물론 그러한 대학입시 과정의 타당성에 대해서야 논리의 다툼이 있을 수 있겠다. 아무튼 지금 말하고자 하는 내용은 통계적 분석 방법은 합리적인 의사결정을 하기 위해 이용된다는 것이다. 수학과 통계학은 ‘현상’을 수식으로 표현하기 위해 상상력을 발휘한다. 문제를 풀고 싶으면 그에 맞는 모델링을 하고 해당 방정식의 해를 찾으면 된다. 자연 또는 사회현상에 대해서 추론하고 불확실한 미래를 대비해서 결정을 내릴 때, 훌륭한 수학자와 통계학자들이 오랜기간에 걸쳐 증명한 과학적인 방법을 이용한다면 꽤 듬직하고 효과적인 무기가 될 것이다. 특히 통계학은 사람이었다면 상상하지 못했을 직감에 반하는 진실을 드러내기도 하며, 사람은 그로 인해 성장할 수 있다.
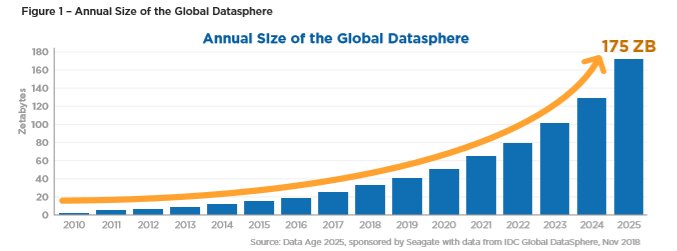
머신러닝 혹은 기계학습의 역사에 대한 글도 언젠가는 작성하고 싶은데, 대략 1949년 Hebb이 Hebbian Learning Theory를 발표하는 데서 시작됐다고 한다. 그 기술이 갑자기 발전하게 된 계기는 근 몇년 사이에 이뤄진 하드웨어나 소프트웨어의 발달이라고 생각한다. 전세계에서 생성되는 데이터 총량은 위 그래프처럼 ‘기하급수적’으로 변화했다. 2010년에 0.xZB, 2016년엔 거의 20ZB, 2018년엔 약 33ZB였다고 한다. 분석 능력을 갖춘 하드웨어도 급격히 발달했다. 이런 데이터를 거두어들일 수 있는 기업도 많아졌고, 학문적인 업적을 산업에서 이용하려는 시도도 함께 증가한 덕에, 통계적 분석 방법을 용용한 머신러닝 기술이 각광을 받고 있는 것같다. 데이터가 증가하면 분석의 정확도가 올라가는 것은 덤이다. 머신러닝은 인간의 학습방법 중 하나처럼, 기계가 경험을 통해 ‘사고’하는 것을 목표로 하는 터라 전통적인 통계학과는 맥이 조금 다르다. 그러나 여느 응용 방법이 그렇듯, 기초지식이 어떻게 응용이 되었는지를 파악하면 보다 정확하게 활용할 수 있고, 새로운 응용을 건축해볼 수도 있을 것이다. 마침 필자는 통계학과 머신러닝의 기초적인 부분을 배울 기회가 있었고, 이를 바탕으로 기초 통계가 어떻게 머신러닝으로 응용될 수 있는지에 대해 정리해보려고 한다.
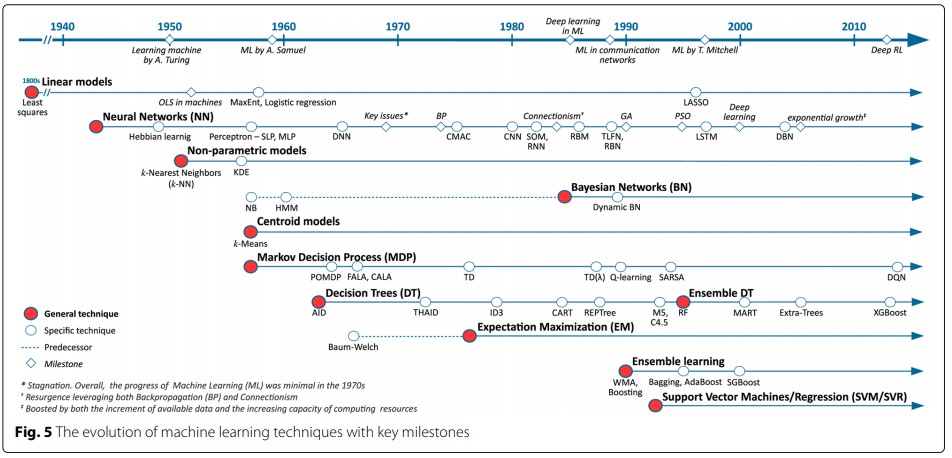
2. 머신러닝 기법의 종류?
앞서서는 통계가 어떻게 현실에서 활용되는지와 머신러닝의 목표는 무엇인지 간단히 적었고, 이번에는 구체적으로 어떤 기법들로 데이터 분석을 하는지 그 종류를 정리하려고 한다. 우선 통계학의 종류를 크게 두 가지로 나눠볼 수 있다. 첫째는 기술통계학으로, 자료의 양이 방대한 경우, 자료의 전반적인 내용을 쉽게 파악하기 위해 정리, 요약하는 방법을 다루는 분야이다. 탐색적 데이터분석이라고도 부르며 데이터를 가지고 있다면 기본적으로 시행해둬야 한다. 두 번째는 추측통계학으로, 모집단의 일부분인 표본 집단을 실제로 관측해서 정보를 분석한 후 모집단의 여러 가지 특성에 대해 과학적으로 추론하는 방법을 다루는 분야이다. 처음 배울 때 확률분포, 추정, 검정, 회귀분석, 분산분석, 시계열분석 등이 다루고, 머신러닝에서 응용되는 분야는 주로 이쪽이다.
머신러닝은 응용수학과 컴퓨터과학 분야의 내용도 포함한다. 데이터는 그 규모가 폭발적일 뿐 아니라, 하드웨어의 발달로 종류마저 한계를 뛰어넘었다. 정형데이터라 불리던 표에 정리된 기존의 데이터와는 구분되어, 비정형데이터인 이미지, 텍스트, 음성 등도 과거보다 효과적으로 분석 가능하게 된 까닭이다. 특히 CNN, RNN 이라 불리는 기법에서 발전해나간 많은 딥러닝 기법들이 비정형데이터 분석에 활용된다. 딥러닝은 신경망 기법(Neural Networks)의 응용으로 머신러닝의 일부이기도 하지만 컴퓨터과학의 컴퓨터 비전, 자연어처리 등의 분야에서 워낙 널리 연구되어서인지 독자적인 개념으로도 자주 언급되고, 그래서 따로 떼어 먼저 작성했다.
이제서야 본론으로 들어가보면 머신러닝은 분석의 목표에 따라 크게 1. 탐색적 데이터 분석(EDA), 2. 분산분석(ABT), 3. 분류예측과 수치예측(CRT), 4. 유형화와 네트워킹 분석(GNT), 5. 딥러닝과 강화학습으로 나뉘는 듯하다. 분산분석은 사실 집단 간의 차이를 분석하는 통계학 내용이다. AB test라고도 하며, 비즈니스에 적용해 두 가지 이상 아이템의 효과 차이를 추론할 수 있다. 수치예측분석은 주로 회귀(Regression)모델을 만들어 데이터를 학습시킨후 새로운 데이터의 수치를 예측하고, 분류예측분석은 회귀모델을 변형하거나 Tree모델 등을 통해 변수가 어떤 범주에 속할지 예측한다. CRT는 데이터에 대한 정보가 미리 지도(정의)된 후 기계가 지도 내용과 데이터 간의 규칙을 학습하고, 새로운 데이터에 대해 이게 0인지 1인지 알아보게 하는 터라 지도학습으로 불리곤 한다. 유형화와 네트워킹 분석은 군집분석, 연관성분석, 주성분분석, 요인분석, 네트워크 분석 등을 포함하며, 기계는 라벨링 되지 않은 데이터 사이의 규칙을 학습하고 데이터를 클러스터로 분할하거나 정보를 알려주는터라 비지도 학습으로 불리곤 한다. 큰 가지로 분류해보기는 했지만 사실 세부 내용은 몹시 방대하고, 주어진 데이터의 종류가 연속적 수치데이터인지, 범주형데이터(이항형, 다항형, 서열형)인지에 따라 적용할 수 있는 분석 기법이 또 달라진다.
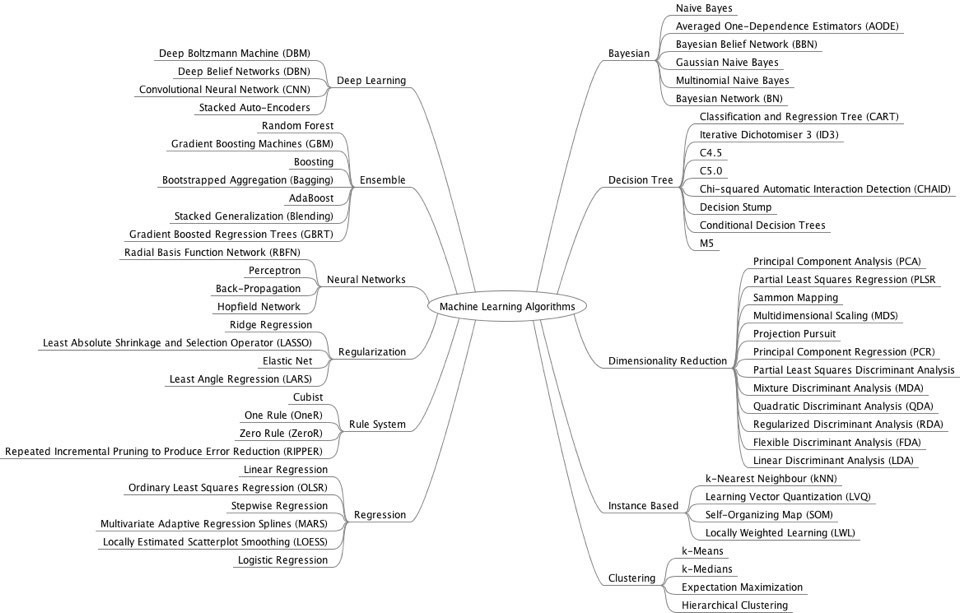
기업이 머신러닝을 이용하는 내용은 대략 다음처럼 예시를 들어보고 싶다. 기본적으로 데이터에 대한 기술통계분석을 마친 후, ABtest를 통해 A상품과 B상품 중 어떤 것이 더 팔기 좋을지 선정한다. 누구에게 팔고, 어떻게 팔지에 도움을 주는 데에서 분류예측과 수치예측이 개입된다. 특정 집단이 A에 대해서 어느 정도 수치로 구매할 것인지, 혹은 특정 집단이 할인행사에 참여하는 고객인지 아닌지 등을 예측해볼 수 있다. 이때 다양한 비지도학습을 이용해서 종속변수에 영향을 미치는 것으로 설정한 독립변수가 너무 많으면 차원축소라는 표현을 쓰며 변수를 줄일 수 있고 고객군이나 상품군을 이런 저런 종류로 군집으로 만들어볼 수도 있다. 여러 집단이 생기면 연관성 분석 등으로 개연성과 유사성을 찾아 상품 추천 알고리즘을 찾는 식으로 머신러닝은 비즈니스에 도움을 주곤 한다.(고 그러더라.: 필자는 그냥 배워서 아는 내용임)
| EVT: Exploratory & Visualization Test | |
| ABT: A&B item Difference Test | 분산분석(ANOVA) 등등 |
| CRT: Classification & Regression | Regression, Decision Tree(CART), Ensemble(Random Forest, Gradient Boosting Machines), Support Vector Machine, k-Nearest Neighbour, Naive Bayes, 시계열분석 등등 |
| GNT: Grouping & Networking | Clustering(K-means, Hierarchical), PCA, FA 등등 |
3. 구체적으로…
(1) 데이터 축소화 분석(data reduction)
- raw 데이터의 분포/특징을 가장 잘 나타내는 대표적인 데이터 유형을 찾아내고 불필요한 잡음(noise)를 제거해줌
- 대표적인 데이터 유형에는 관찰치와 변수컬럼을 대상으로 그룹핑/유형화/묶음/축소화 등의 유사작업을 수행함
(2) 축소화/유형화 분석의 종류
관찰치를 묶어서 데이터를 축소함: 군집분석 / 다차원척도분석 / 연관분석
- 군집분석(clustering Analysis)
- 다차원척도분석(Multidimensional Scaling)
- 연관분석(Association Analysis; Basket Analysis)
변수컬럼을 묶어서 데이터를 축소함: 주성분 분석 / 요인분석
- 주성분(Principal Componnent Analysis)
- 요인분석(Factor Analysis)
4. 연관분석(A Priori Algorithm)
5. 군집분석(clustering)
- 여러개의 관찰치/관측치/사례/케이스/레코드들을 대상으로 특성이 유사한 것끼리 하나의 그룹으로 묶어줌
-
일종의 데이터 축소화(reduction) 분석에 속함
- 군집분석으로 그룹핑을 한 후 따로 연관분석을 들어가도 디테일한 분석이 가능할 것이기에, 다른 분석 하기 전에 쓰는 기법.
(1) 크게 2가지 방식의 군집분석 기법이 있음: 계층적 / 분할적
계층적/위계적/응축적(hierarchical)/탐색적(exploratory) 군집분석
- 데이터변량차이가 가장가까운 2개 관찰리를 하나의 군집으로 응축해 시작해 계속 거리차이가 가까운 군집들과 응축해 나가는 방법
- 최대한 나눌 수 있을 만큼/ 그룹핑 할 수 있을 만큼 해줌
- 한 번 그룹핑된 관찰치를 다른 그룹에 넣을 수 없음
- hclust()
분할적(partitioning)/확인적(confirmatory) 군집분석
- 분석가가 군집의 갯수를 알고리즘에 지정/입력한 다음 해당 그룹핑 작업을 시킴
- 대상 관찰치들을 어느 분할된 그룹에 입력했다가 그 그룹의 변량차이에 어울리면 놓고, 아니면 다른 그룹에 이동해서 다시 그 그룹의 변량계산 함
- kmeans(), cluster::pam()
6. 주성분분석(principal component analysis: PCA)
- 선형적 결합이 중심
- 주어진 변수들간의 개념적 상관성 보다는 수치적인 상관성이 있는지, 즉 모든 변수들의 공통적인 선형적인 데이터 변화량을 전체적으로 고려하여 뚜렷하게 관찰되는 대표적인 변화량을 주성분(principal component)으로 통합함
- 보통 2-3개 정도의 성분을 추출하는데, 제1주성분의 변화량(설명령)이 가장 크고/강해서 전체적인 변수들을 대표하는데 있어 상대적인 중요도가 크다고 할 수 있음
- 도출된 주성분들의 변화량(설명력)을 합쳤을 때 85%정도 이상이면 무난하게 주성분이 도출된 것으로 봄
- 나머지 설명력이 작은 주성분들은 더 이상 추가해도 의미가 없음
- 제1주성분이 분산이 크고 변동성 제일 많이 가져와서 성분을 만들기 때문에 제일 중요한 움직임.
7. 요인분석(explotory factor analysis: EFA)
- 잠재구조 결합이 중심
- 주어진 모든 변수들 간의 수치적인 상관성인 선형적 결합보다는 전체변수들 중에서 개념적/논리적으로 주제가 비슷한 몇 몇 변수들을 잠재적인 요인(factor)으로 통합하여 만듬
- 도출되는 요인의 갯수는 제한없이 여러개가 도출 될 수 있으며, 하나의 요인에 결합되는 변수들의 갯수도 서로 다를 수 있음
- 각 요인간 상대적인 중요도 차이는 없지만 도출된 요인들의 개별 설명력을 합친 누적설명력의 합이 85% 이상일 때의 요인갯수가 적정한 것으로 판단함
- 특정 변수의 중요도가 특별히 있다고 볼 수는 없다.
(1) 주성분분석과 요인분석의 공통점
변수 축소 기능(차원의 저주를 해소하는 기법)
- 전형적인 데이터 축소기법으로 여러 개의 변수데이터를 활용해서 공통적인 새로운 변수들을 만들 수 있음
- 서로 상관관계가 있는 여러 개의 변수들을 선형결합으로 만들어 대상으로 변수가 가진 자료의 분포내용(변동)을 최대한 보존하는 축소된 개수의 변수로 변환시키는 방법
- 예) 인구통계학적 조사 중 신장, 몸무게 등의 변수는 같이 묶일 수 있는 것이 그 예. 연관성이 있을 수 있으므로.
데이터 패턴탐색 용이
- 여러 개 변수들이 아닌 축소된 몇 개의 주성분/요인을 통해서 주어진 데이터에 대한 이해도가 높아지고 관리용이성도 커짐
다른 분석을 위한 사전분석 역할
- 회귀분석 등에서 독립변수간 다중공선성문제(Multi-collinearity)이 존재할 경우 상관도가 높은 변수들을 하나의 주성분 혹은 요인으로 축소하여 회귀분석모형개발에 활용함
- 주성분 또는 요인분석을 통해 차원을 축소한 후에 군집분석을 수행하면 군집화 결과, 연산속도가 개선됨
- 기계에서 나오는 다수의 센서데이터를 주성분분석이나 요인분석을 하여 차원을 축소한 후에 시계열로 분포나 추세의 변화를 분석하면 기계의 고장(fatal failure) 징후를 사전에 파악하는데 활용
(2) 주성분분석과 요인분석의 차이점
축소를 통해 새롭게 생성된 변수의 수
- (요인분석) 요인의 갯수를 사전에 지정하는 것이 아닌 분석과정에서 결정됨
- (주성분분석) 보통 4개 이하의 범위에서 성분을 생성함
● 주성분: 만약 변수가 100개면(개별 레코드 설명하는 변수가 100개면) 주성분은 3개에서 5개 정도로 묶는다. 변수가 몇 개 던지 간에 대표적으로 관찰되는 변수만 골라서 확 줄여준다.
● 그래서 만약 성분이 4개 일 때 1번 성분의 주제가 뭔지 명명하기 쉽지 않다. 그래서 프로파일링할 때 이름을 명명하지 않고 제1주성분, 제2주성분으로 표현.
● 요인분석: 주성분과 원리는 똑같이 상관성 기반으로 갖고 옴. 얘는 주성분과 달리 허들이 있다. 상관성 0.3, 0.5 정도 되지 않는 건 결합시키지 않는다. 학계마다 다른데, 보통 상관성 0.4 이상, 좀 좋은 건 0.6, 0.623 등 이상인 변수끼리만 묶는다.
● 두 개가 하나로 묶이면 요인이 될 수가 있으니, 요인분석은 여러개의 요인이 나올 수 있다.
● 요인분석의 취지는 상관성이 낮으면 같은 주제로 보지 말자는 컨셉이 들어 있는 것. 얘는 새 변수들을 명명해줌.
● 공통변량: 요인분석은 애만 씀.
● 고유변량: 아무하고도 결합되지 않는 독자적인 데이터 움직임. 주성분은 공통변량도 쓰지만 이왕이면 데이터 버리지 말고 통합시키려느 시도라 독자적인 데이터도 가져와 성분을 만듦.
새롭게 생성된 변수이름 명명
- (요인분석) 분석가가 요인에 묶여진 변수들을 토대로 명명함
- (주성분분석) 공통분산(주성분)크기순대로 제1주성분, 제2주성분 등으로 표현함
새롭게 생성된 변수들 간의 중요도
- (요인분석) 새롭게 생성된 변수들 간에는 대등한 관계임
- 어떤 요인변수가 더 중요하다고 볼 수 없음
- (주성분분석) 제1주성분이 분산의 변동량을 가장 많이 가지고 있으므로 가장 중요하며, 그 다음으로 제2-제3-제4 주성분임
분석방법의 실제 의미
- (요인분석) 목표변수를 고려하지 않고 주어진 데이터들간의 상관성을 토대로 비슷한 변수들을 묶어서 새로운 잠재변수를 만들어 냄
- (주성분분석) 목표변수를 고려하여 목표변수를 잘 예측/분류할 수 있는 선형결합으로 이루어진 몇 개의 주성분을 찾아냄
● 변수 너무 많아서 현상을 이해하기 힘들 때 변수 축소하면 잠재구조(상위레벨의 변수)를 파악할 수 있다. 상위레벨의 개념으로 보면 쉽게 변수들의 주제영역을 파악할 수 있다.
● 주성분분석은 머신러닝에서 많이 쓴다. 중요한 건 결과, 즉 종속변수의 예측이 중요한 것이기 때문에 변수의 속성은 이해할 필요가 없거든.
● 요인분석은 예측은 예측이고, 독립변수가 너무 많을 때, 어떤 식으로 관리할 지 알고 싶을 때 이용. 변수들의 구조, 패턴을 보고자 할 때.
8. 비교차이(A/B테스트)와 예측분석(prediction)
(1) A/B/n Test
- 비교대상 액션아이템 중에서 목표로하는 성과를 가져다 주는 것이 어떤 아이템인지를 성과차이를 비교해 선택하는 문제유형
- 목표로 하는 성과의 달성 여부를 어떤 기준을 가지고 할 것인가?
- Y/N(이항형), Norminal(다항형), Ordinal(서열형), Average(평균형)의 4가지 기준을 통해 액션아이템의 성과를 비교분석함
- 이 중에서 Y/N(이분형), Norminal(다항형), Ordinal(서열형) 기준으로 아이템의 성과를 비교할 때 비율분석/카이자승 분석이 중심
- 이 중에서 Average(평균형) 기준으로 아이템의 성과를 비교할 때 T검정(t.test), 분산분석(anova)이 중심
(2) Prediction Test
- 테스트된 아이템을 가지고 실제로 액션을 취했을 때 아이템의 성과가 어떤조건에 따라 달라지는지를 판단하는 문제유형
- 테스트된 아이템을 가지고 실제로 액션을 취했을 때 왜 성과차이가 나는가?
- Y/N(이분형), Norminal(다항형), Ordinal(서열형), Average(수치형)의 4가지 성과를 다르게 발생시키는 조건/요인/속성/변수/기준/피처(feature)와 이들이 가지는 임계치(성과다 달라지는 경계값)을 도출함
- 피처 + 임계치 = 규칙
- 이중에서 Y/N(이분형), Norminal(다항형), Ordinal(서열형) 성과를 발생시키는 규칙을 찾는 문제를 분류예측(classification)이라고 함
- 그리고 Average(평균형) 성과를 발생시키는 규칙을 찾는 문제를 회귀예측(regression)이라고 함
(3) 회귀분석(regression)
- 사전에 고객의 반응들을 수치/양적 데이터로 측정하고 이 수치를 대표하는 평균값을 만들어 내는 기준/규칙/피처(feature)/속성/변수를 도출함
- 즉, 속성변수와 그 임계치를 알아 낼 수 있다면, 특정한 평균값을 충족하는 목표고객을 대상으로 마이크로 타겟팅이 가능해짐
9. 분류분석(classification)
- 사전에 정해진 유형으로 고객을 구분하는 규칙을 도출함
- 사전에 정해진 유형 중에서 목표로 하는 고객유형도 있으며, 그렇지 않은 고객유형도 있음
- 이들을 구별할 수 있는 기준/규칙/피처(feature)/속성/변수, 즉 속성변수와 그 임계치를 알아 낼 수 있다면, 목표고객을 대상으로 마이크로 타겟팅이 가능해짐
10. A/B테스트와 회귀분석을 통한 동일한 문제에 대한 차별적 접근
-
A/B 테스트를 통해 선정한 아이템을 가지고 고객 100명에게 액션을 취했을 때 반응이 평균 5만원 정도로 나왔다. 이 성과를 6만원으로 높일 수 있는 방법은?
-
(1) <A/B테스트 방식> 또다른 대안 C, D 등를 만들어 A/B 테스트를 진행해 목표로하는 성과평균값이 나오는 아이템을 선정함
-
(2) <회귀분석 방식=""> 기존의 반응금액 데이터를 이용해 반응금액을 결정하는 규칙(피처+임계치)를 찾아낸 다음 이 규칙을 통해 6만원 이상의 반응을 보일만한 고객한테만 액션을 취하면 됨
예))
할인쿠폰과 적립쿠폰이 있다. 마케팅 프로모션 담당자가 두 가지 아이템을 기획했을 때, 동일한 예산 들여 이벤트 진행했을 때 반응이 좋을지 나쁠지 궁금하다. 이 기준은 어떻게 결정해야 할까? 그 기준을 범주와 연속에서 판단하더라, 라는 판단은 이미 내려져 있다.
첫째 결정 방법은 이항형. 쿠폰을 썼냐, 안썼냐의 관점: Yes/No(이항검증). 할인쿠폰은 70/100이 썼고, 적립쿠폰은 60/100이 썼더라.
둘째 결정 방법은 다항형. 이 기준으로도 결정 가능: 클릭 전환율. 이것도 중요한 KPI이다. 클릭하고 사용/클릭하고 사용 안함과 같은 기준도 사용할 수 있고, 할인 쿠폰을 줬더니 주로 어떤 제품을 사는데 쓰더라, 적립 쿠폰을 줬더니 어떤 제품을 사는데 쓰더라, 같은 기준으로 판단할 수도 있다. 쿠폰을 어느 요일에 쓰더라.
셋째 결정 방법은 서열형. 쿠폰 줬더니 물건 구매 금액 범위 별 쿠폰 사용 고객(서열형 척도)
분석 모델링: 문제에 대한 가설 설정하고 문제 해결 위한 변수 설정해서 변수 간의 관계를 찾아내는 방법. 변수를 설정하고 그들이 어떤 종류에 속하는지를 찾아내어야 한다. 모델링할 때, 변수를 이항/다항/서열/등간/비율 중 어떤 종류로 설정할지 정해야하고 그래야 조사를 편리하게 할 수 있다.
CMO(마케팅 담당 임원) 입장에서는 클릭률, 클릭전환여부가 굉장히 중요하다. 마케팅은 돈을 쓰는 부서인데, 쓴 돈에 대해서 반응 보이냐가 중요.
CFO(돈 관리하는 담당 임원) 입장에서는 돈 들인만큼 물건 사는데 고객이 얼마 썼는지가 궁금하다.
그러니까, 이 이야기 하는 건, 실제 현장에서 프로젝트 진행 후 이해관계자에 따라 설명해야 하는 지표 등이 달라질 수 있다는 것.
----------------------------
예를 하나 더 들어보자.
영업사원 대상으로 교육 실행. 집체 교육도 할 수 있고, 온라인 교육 등이 있다.
영업사원들이 교육을 잘 받아서 영업 능력이 오른 것을 어떻게 평가할 수 있을까?
이항형: 예전 매출보다 10%이상 증가 되고 안 되고 에 따라 평가.
시험 쳐서 패스 논패스.
기업대상으로 할 경유, 교육 후 대기업 영업됐냐에 따라 평가.
다항형: 영업 교육 별로 시험 쳤을 때 패스 논패스
영업 교육 후 지역 별 실적 변화
영업 교육 후 대상 종류(제조, 생산, 유통...) 별 실적 변화
서열형: 교육 후 영업 대상을 종류별(대기업, 중견기업, ...)로 나누어 실적 변화.
등간형 중도절단형 비율형: 집체 교육 받은 직원들 매출 평균과 온라인교육 받은 직원 매출 평균 비교해서 평가.
비율형: 출석률, 코스 수료율.
- (cf) 강화학습(Reinforcement Learning)은 분석가가 모델링을 통해 선정된 변수들만을 투입해 규칙/피처(feature)를 찾는 것이 아니라 알고리즘이 탐색을 통해서 피처를 선정 찾아내 투입/반복하면서, 점점더 강한 예측력을 가진 알고리즘으로 업그레이드됨
A/B테스트와 분류분석을 통한 동일한 문제에 대한 차별적 접근
- A/B 테스트를 통해 선정한 아이템을 가지고 고객 100명에게 액션을 취했을 때 반응이 10명정도 나왔다. 이 성과를 20%로 높일 수 있는 방법은?
(1) <A/B테스트 방식> 또다른 대안 C, D 등를 만들어 A/B 테스트를 진행해 목표로하는 20% 성과가 나오는 아이템을 선정함
(2) <분류분석 방식=""> 액션대상인 고객 중에서 반응을 보일 것으로 예상되는 50명한테만 액션을 취해서 10명 정도의 반응을 이끌어 내면 20%가 달성됨
추가. 몇가지 용어 정리
- 예측변수 = 원인변수 = 독립변수 = 피처 = 입력변수 = 설명변수
- 반응변수 = 결과변수 = 종속변수 = 타겟
- 성과변수 = KPI (Key Performance Index)
- 관찰치 = record = 행 = 사례(케이스)
- 변수 = 컬럼 = 열
- 인덱싱 = 셀렉션: 보통 컬럼 선택하는 행위
- 필터링 = 슬라이싱: 보통 행(레코드) 선택하는 행위
raw data 받을 수 있는 웹사이트
- 공공데이터포털
- 서울열린데이터광장
- 경기도데이터포털
- K-ICT빅데이터센터 데이터큐브
- 데이터진흥원데이터스토어
- SKT 빅데이터허브
<참고 문헌="">
- 최점기 박사님 강의